Minería de datos
Introducción
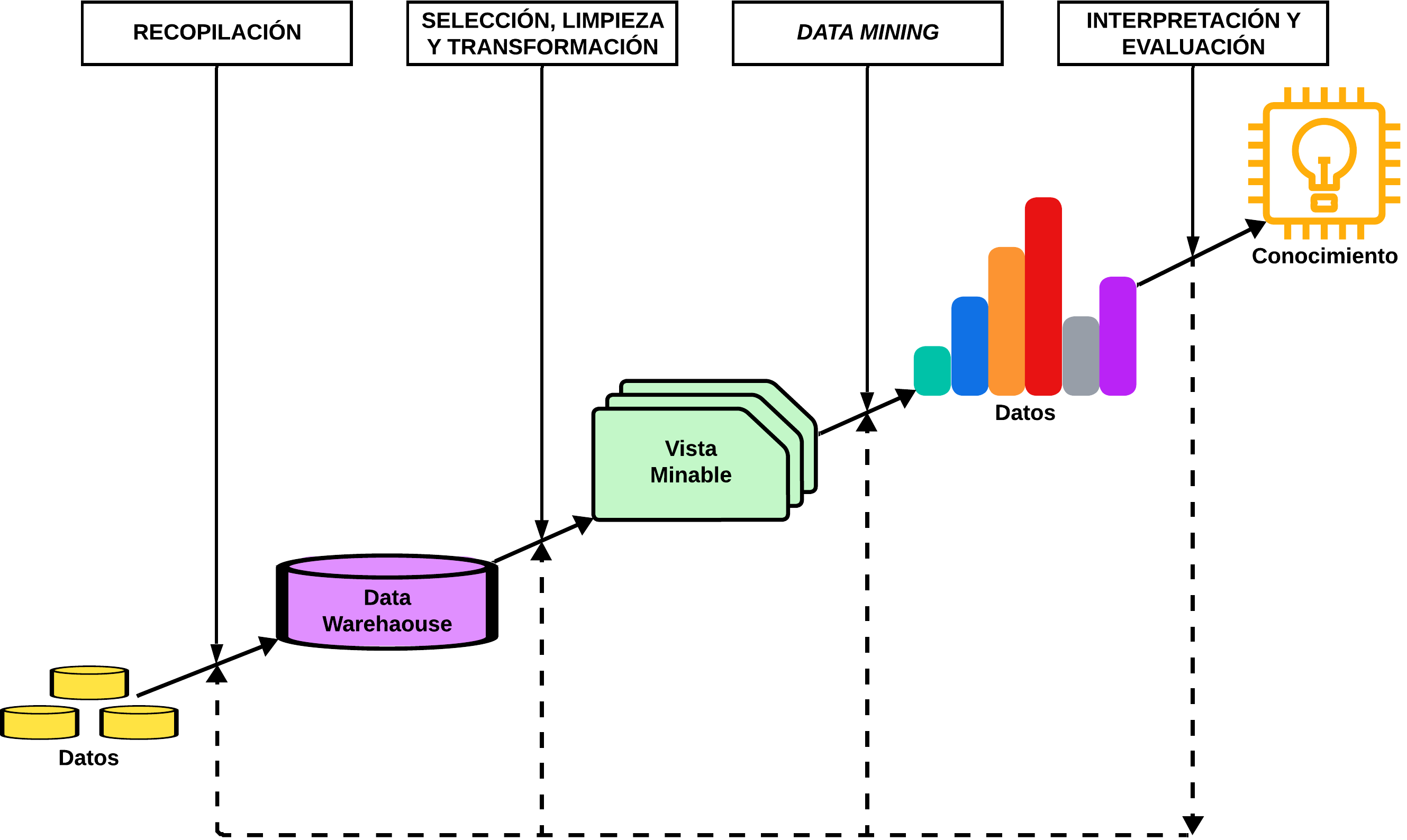
La minería de datos surge a partir de la creación de almacenes de datos, donde la gran cantidad de datos puede servir al sistema para obtener reglas y estructuras útiles. De ahí que esta técnica se utilice para realizar procesos estadísticos automáticos o semiautomáticos para encontrar dichas reglas. Se podría decir que la minería de datos intenta buscar el conocimiento utilizando los datos almacenados en grandes bases de datos.
De forma general, los datos son la materia prima bruta. En el momento que el usuario les atribuye algún significado especial pasan a convertirse en información.
Lo que en verdad hace el data mining es reunir las ventajas de varias áreas como la Estadística, la Inteligencia Artificial, las Bases de Datos y el Procesamiento Masivo, principalmente usando como materia prima las bases de datos.
La minería de datos proporciona las herramientas necesarias para explorar esta cantidad ingente de datos de un Data Warehouse y extraer de ella información relevante.
Estas herramientas consisten en métodos estadísticos que permiten identificar patrones de comportamiento y conexiones en unos datos que, por sí solos, no significan nada.
El objetivo principal de la minería de datos es extraer información relevante de los datos.
Otras funcionalidades de la minería de datos son:
Eliminar ruido de los datos.
Extraer información relevante de los mismos y evaluar posibles resultados.
Tomar decisiones de negocio mejores y más rápidas.
Procesos
De manera general, podemos identificar tres etapas en el proceso de minería de datos:
La exploración inicial de los datos: se preparan los datos haciendo una limpieza de estos, seleccionando subconjuntos y, en caso de conjuntos muy grandes, seleccionando qué atributos son más interesantes.
La construcción del modelo: se seleccionan varios modelos para elegir cuál es el que mejor se adapta al objetivo. Normalmente, en esta etapa se hacen ensayos con los diferentes modelos sobre subconjuntos de los datos y se toma la decisión en base al rendimiento ofrecido por cada uno.
La implementación del modelo en los datos: implica utilizar el modelo seleccionado en la etapa anterior y aplicarlo a nuevos datos para generar predicciones o estimaciones del resultado esperado.
Utilidades
Como sabemos, un almacén de datos contiene un gran volumen de datos que pueden servir a una corporación para mejorar su plan de negocio. Por ello, la utilidad más inmediata de la minería de datos es la predicción, la cual puede tener diferentes características y motivaciones.
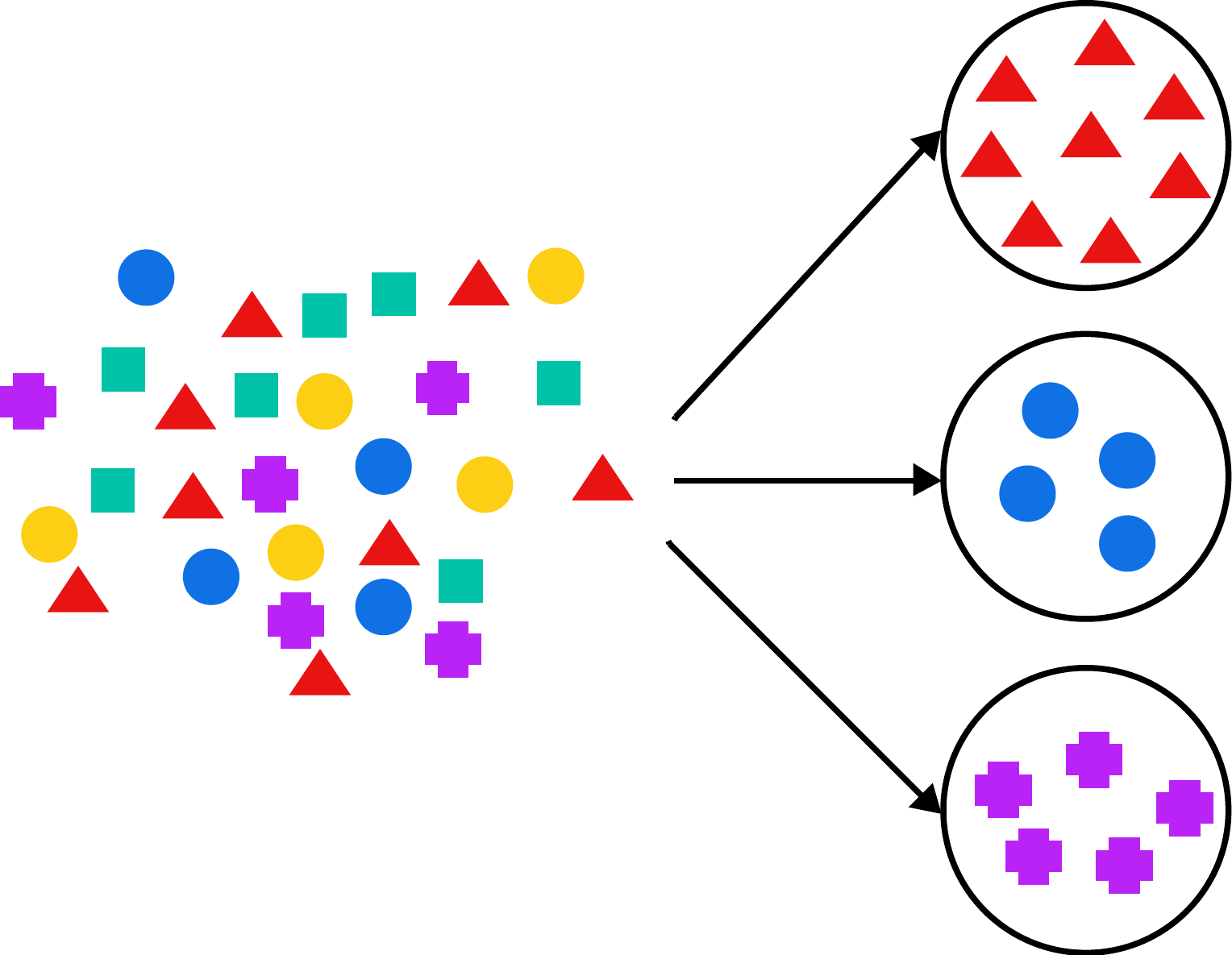
Clasificación
Un tipo especial de predicción es la clasificación ya que, dados unos datos, trata de determinar a qué clase pertenece un elemento nuevo. La predicción se basa en atributos conocidos de los datos y se puede utilizar, por ejemplo, para decidir si conceder un crédito a una persona.
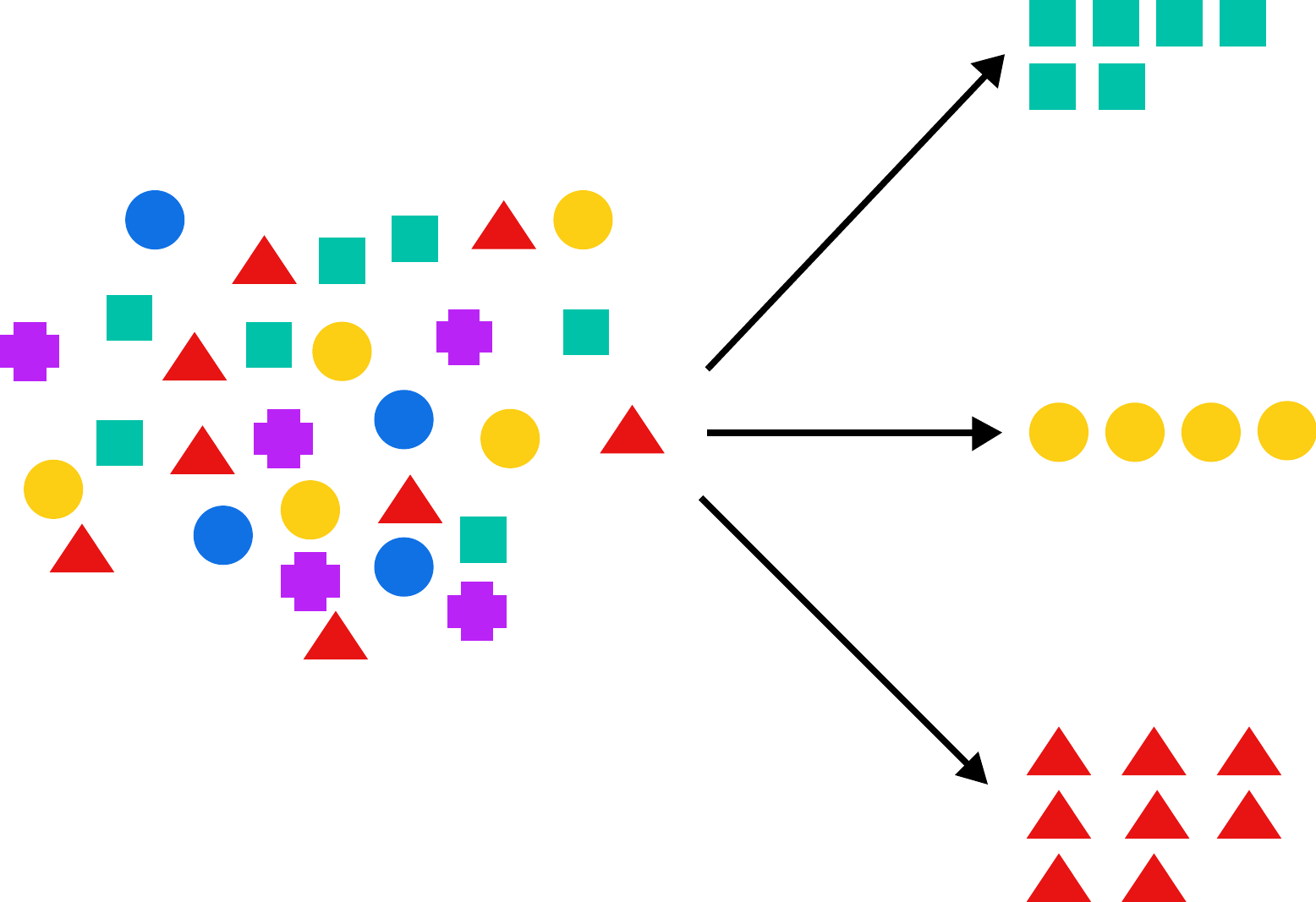
Asociación
Otra utilidad de la minería de datos es la asociación, por ejemplo, buscar los productos de una tienda que se compran a la vez. Al determinar estas asociaciones se pueden generar recomendaciones de compra para otros clientes.
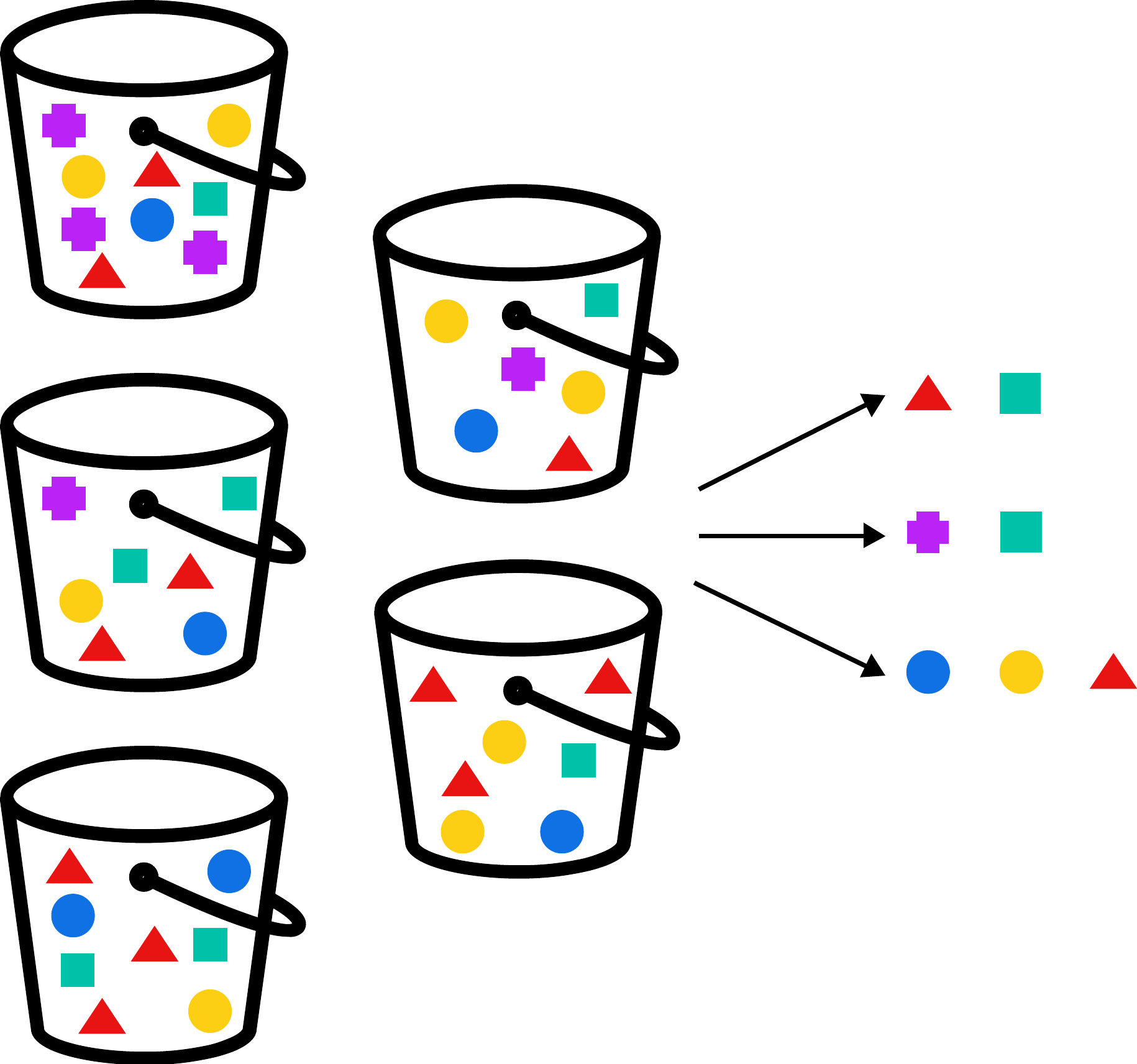
Agrupación
Por último, tenemos las agrupaciones, que son un tipo especial de asociaciones. Las agrupaciones permiten hallar agrupaciones de puntos en los datos. Esto puede servir para detectar diferentes tipos de usuarios en aplicaciones online, como puede ser un comercio electrónico, o en otro ámbito distinto, detectar tipos de jugadores.